Searching data from DynamoDB in three simple steps
Contents
It’s well known that DynamoDB works well for lookup queries. But if you need to run heavy, analytical queries against the data in the DynamoDB table, you would need to use other tools for indexing data. One of the solutions you can come across in the AWS documentation and AWS blog posts is to use DynamoDB streams to load data to the AWS ElasticSearch service for indexing and providing a reacher search possibilities to users.
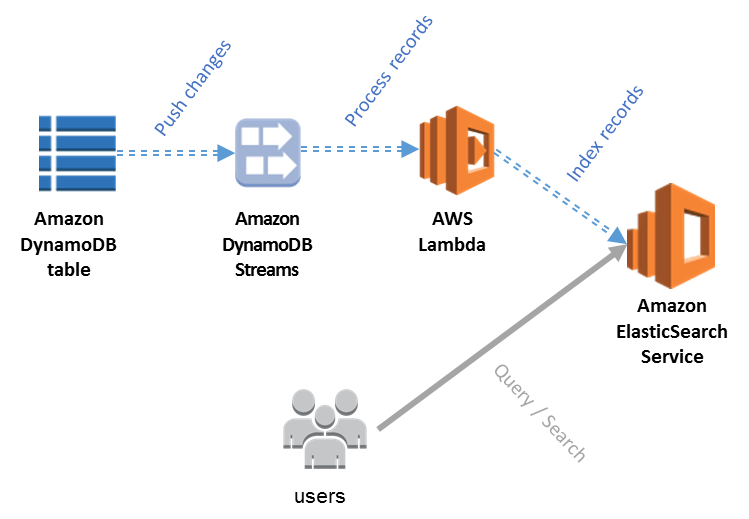 The image is from the original post in aws blog.
The image is from the original post in aws blog.
This time I decided to make all configurations via the provisioning tool - terraform. This will help to avoid too many screenshots of the AWS console and better show in the end, that the setup of this configuration consists indeed of three simple steps.
As usual the final code could be found the GitHub repository. All the pre phrases were said, let’s get started.
DynamoDB table
For the beginning we need to describe a table, which we are going to synchronize with ElasticSearch. As an example, I created some variation of the transactions table.
|
|
The crucial part here is stream_enabled = true. it creates the DynamoDB stream,
which capture the changes happening in the table. The stream retains rows for 24 hours to be consumed by something, by Lambda in our case.
In this particular example, we are going to capture only new version of the row (stream_view_type = "NEW_IMAGE"), although the capturing logic could be a bit more complicated.
Processing stream Lambda
Now it’s time to create the Lambda function to consume events coming from DynamoDB and push them to the AWS ElasticSearch service. Let’s create function:
|
|
Let me describe few things in this snippet. I am using the nodejs runtime for the function code, the same logic could be implemented
in any runtime supported by AWS. The code is take locally (more details a little bit later) from the zip-file, for the production ready solution,
probably could be used deployment via S3. Also, the function will need to know the ElasticSearch host, where to send the messages. This information
provided to it through the environment object and taken as an output from the terraform module for the ElasticSearch.
Let’s assign the function to the event source:
|
|
the var.stream_arn is the output of the DynamoDB creation module (see the GitHub repository for more details).
Also we need to add needed permissions to the Lambda role:
- it will need access to the DynamoDB streams reading,
- access to the CloudWatch logs to write its own logs,
- and finally access for calling the ElasticSearch domain.
|
|
Lambda function code
And here’s the main part - the actual Lambda code, which makes the magic:
|
|
There is no special part of AWS SDK for making ElasticSearch calls, but luckily there are other ES clients could be easy found, I only need to
be sure, that the clients send authenticated and signed request. For that I will use nice little library http-aws-es.
Putting all together and have this small snippet of code above, which does the job - pushing new rows in DynamoDB table to the transactions index.
Packing everything to zip file and we are ready to deploy our Lambda function.
|
|
ElasticSearch
The last puzzle piece, but not least. Let’s create the ElasticSearch domain now. Before starting, I would comment here that the configuration of the ES domain is quite flexible and diverse, that’s why I would say it’s a bit overcomplicated also. But if you are not afraid of getting a bit deeper into the details of configuration, that should be totally fine.
First of all, I have to notice, that I wanted to show the outcome of this setup in some pleasant way and decided to use the Kibana, which comes with AWS ElasticSearch out of the box. The only problem here, that I didn’t want to setup also the security layer for the Kibana instance (it has a few SSO-kind of options), so I just opened the ES domain to public. But in case of production ready solution, you would need to keep ES in the private network or configure proper security for it.
Saying that, let’s take a look how we are creating AWS ES Domain by means of terraform module:
|
|
warning
In the policy, the first rule grants all actions to all principals - that is what should be adjusted.
Additionally, I have configured the output to show the Kibana endpoint, where final data can be checked:
|
|
The Test
Now the fun part came, let’s build our infrastructure and run the test.
|
|
after a few minutes, you can find in the console something like that:
|
|
Before going to the specified URL, let’s put a row in the DynamoDB table:
|
|
A few moments later, we can see in Lambda logs, that the new event was processed:
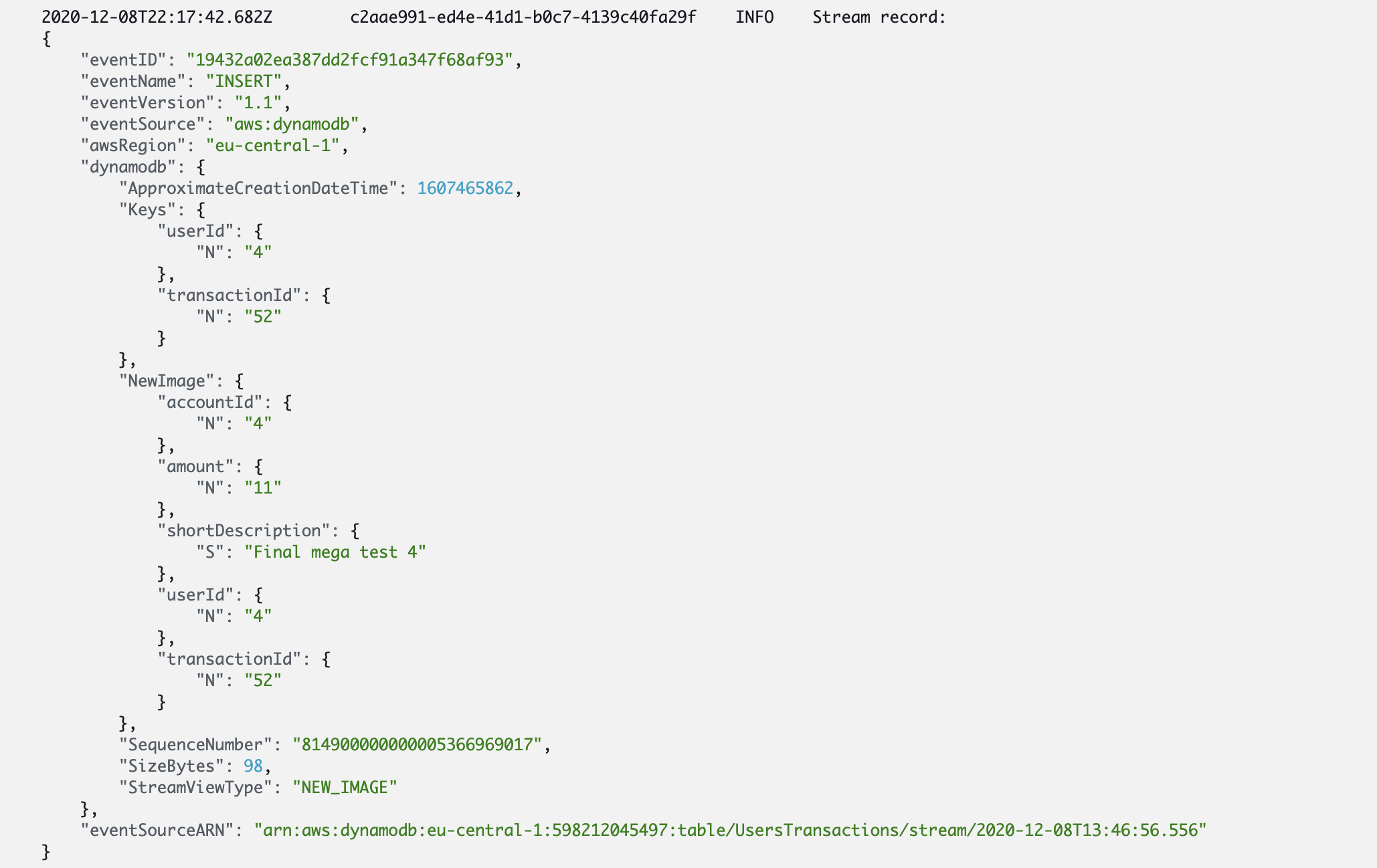
and if go to the Kibana interface, we can see the entries of our transactions index:
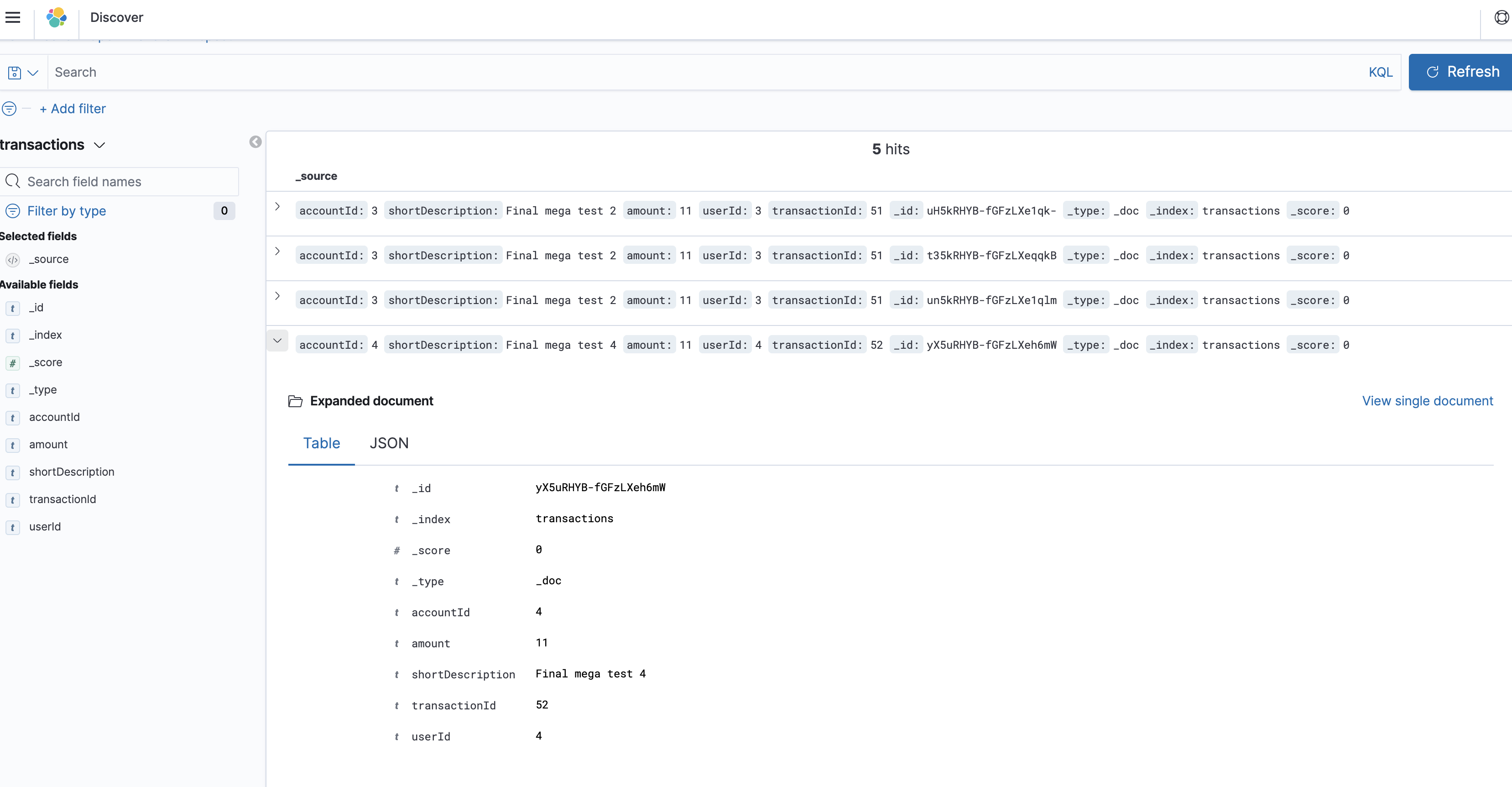
Now we are free to search our data securely stored in DynamoDB and indexed in the AWS ElasticSearch.
Conclusion
The solution described here is indeed quite simple and natural for the AWS services. The usage of provisioning tools like terraform makes it event smother. The simplicity comes also with good durability of the solution because the services used were designed to be integrated with each other as a result we need to write relatively less code to achieve a quite powerful result.
Update: I wrote the second part about the alternative way of getting the same result.
Author Relaximus
LastMod 2020-12-08